
2023巅峰极客ezlua
关于lua:https://woaw04.github.io/2024/01/15/lua/
0x00 题目分析
一道luajit
涉及有lua虚拟机,lua结构,lua执行流程
使用了ASLR,地址不可信,方法更重要
博客断断续续写了一段时间,所以可能图内的地址对不上,不过方法思路应该是没问题的(
0x01 输入数据的处理
进入main函数,翻到最下面,可以找到一个函数:luaL_loadbuffer

此函数需结合luajit2.1的源码进行分析
从lj_load.c中可以找到关于luaL_loadbuffer的定义
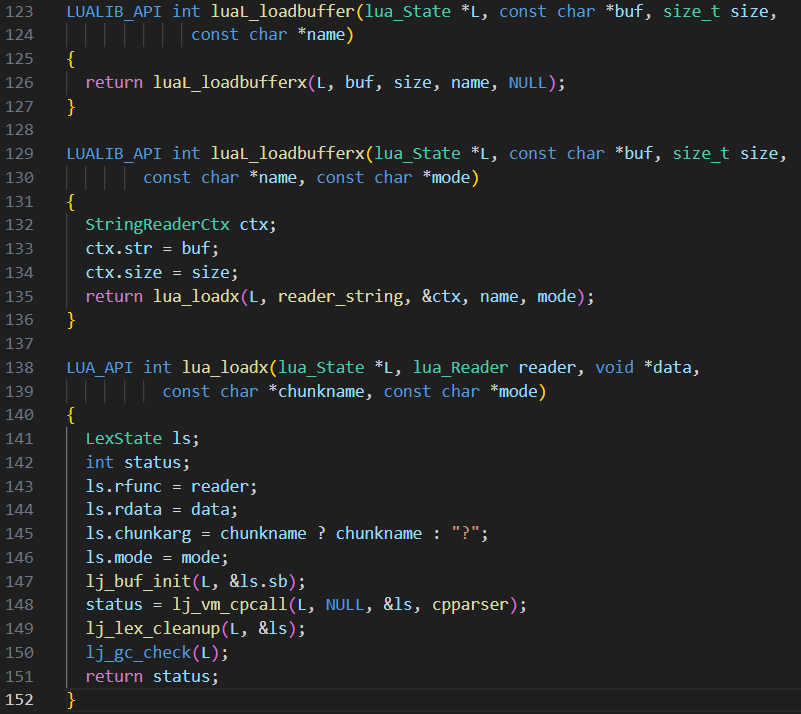
此处为了方便观看,我将这三个函数放在一起,并按调用的顺序进行了排列,可以看到,在luajit中,luaL_loadbuffer函数是调用了luaL_loadbufferx函数,而luaL_loadbufferx函数中又调用了lua_loadx函数
这条调用链的作用是载入并编译内存中的一段Lua代码,然后作为一个代码块 (称为chunk)压入栈中。
在lua_loadx函数中变量status有一项为cpparser,其作用是将 Lua 源代码解析为 Lua 函数,并将其保存在 Lua 虚拟机中,以供后续执行
函数cpparser如下:

在函数中,变量pt用于判断加载的Buffer是binary文件还是text文件,如果为binary文件,则调用lj_bcread进行处理,否则调用lj_parse处理
有些题目会对lj_bcread或lj_parse进行改造,从而实现一些操作,但这题没有,以后遇到了可能改一下这篇博客(
由于这题没有在这里做文章,因此需要动调来看看输入的数据怎么处理了
由于luajit使用了虚拟机,因此会将数据另外放到内存的一个位置,然后再进行处理,这个位置便是luajit划分出来的字节码区域,而用户输入的数据自然也需要经过处理后放到这,所以在进行输入数据的跟踪时,需要等到程序将用户输入的数据处理完、放入字节码区域后再去跟踪放入字节码区域的数据,否则跟踪原来的未经处理的数据是进不去luajit的虚拟机内部的
因此可以在loadbuffer这个位置下一个断点,等待数据传入到VM内
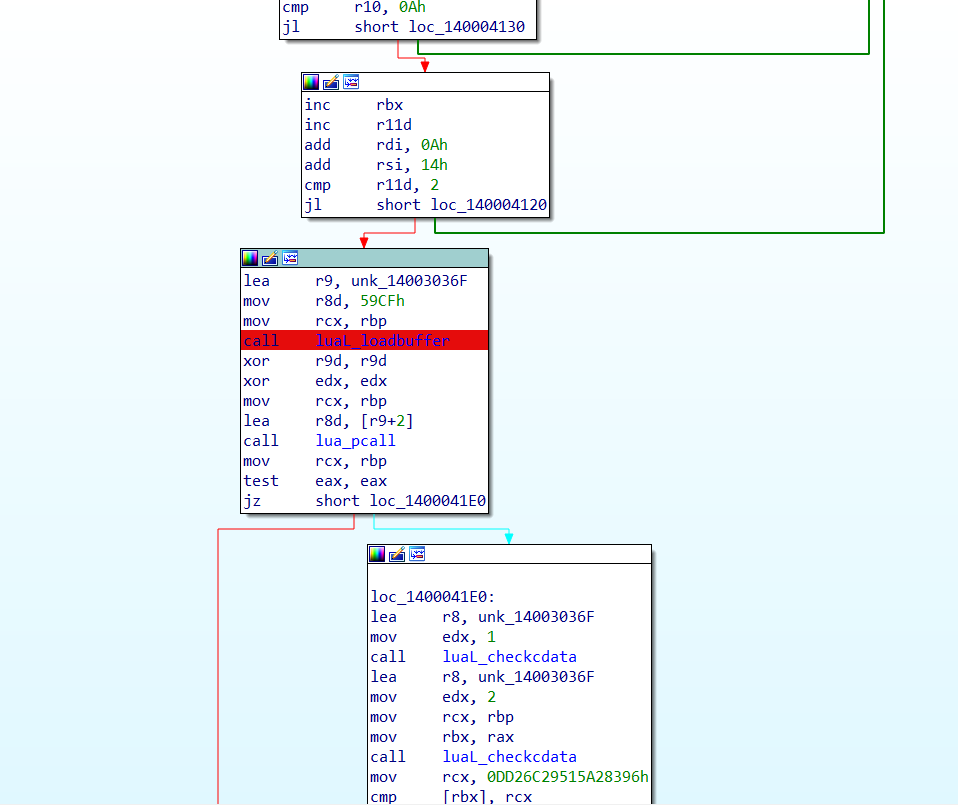
由于程序有字符串长度判断和格式判断,所以在构造数据的时候尽量符合这些判断条件,以免带来不必要的麻烦(

在这里首先使用1123456789112345678911234567891123456789作为输入,如果后面有其他需求再进行更改

直接跑,让程序断下
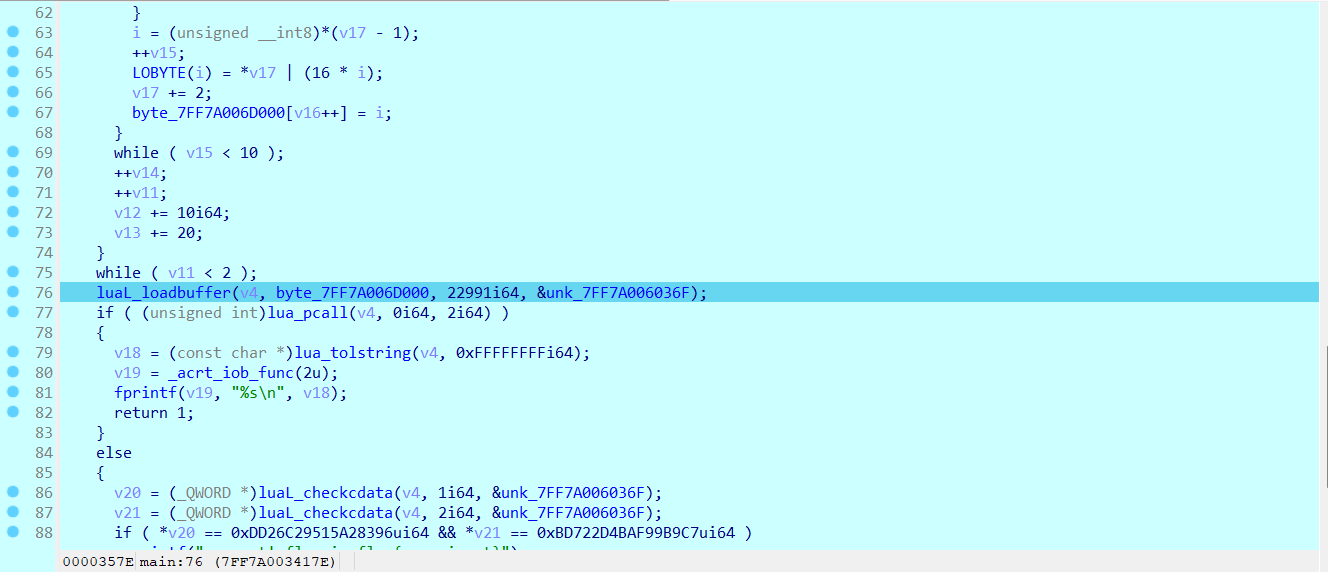
然后在内存中搜索输入的字符串

可以看到字符串前面和中间多了一个03,这个说明这段数据可能就是处理后的数据了,因此可以在数据开始的位置下一个内存访问断点,从而看看这段数据后面被怎么处理了
下完内存断点后继续运行,可以发现断在了这个inc rdx的位置,这个位置非常奇怪,因为上面没有函数头,所以可能是IDA没有识别出来,可以在上面很多0CCh之后的第一个48h处将此位置识别为函数

可以看到识别是成功的,而且函数能被正确地进行反汇编


这个函数是对 uleb128格式数据的解码,据此去luajit中查找,可以在lj_buf.c中找到lj_buf_ruleb128这个函数,对比发现一致
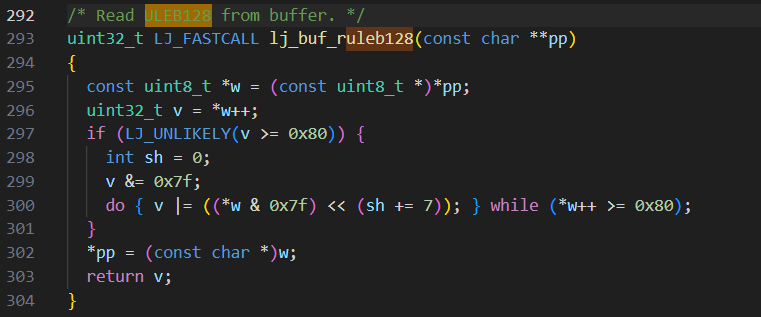
在此补充一下uleb(Unsigned Little Endian Base)编码:uleb通过字节的最高位来决定是否用到下一个字节。如果最高位为1,则用到下一个字节,直到某个字节最高位为0或已经读取了5个字节为止。对于函数lj_buf_ruleb128而言,它读取1-5字节。
举个例子,uleb128解码
1 | 假设有以下经过uleb128编码的数据(都为16进制)--81 80 04 |
再举个例子,uleb128编码
1 | C0 83 92 25计算uleb128值: |
再补充一下,luajit中lj_buf_ruleb128并不直接使用,而是像上面提到的loadbuffer一样有个调用链,在lj_bcread.c中可以找到函数bcread_uleb128调用了lj_buf_ruleb128,因此在对源码进行查找的时候不能直接搜lj_buf_ruleb128,而是应该搜bcread_uleb128
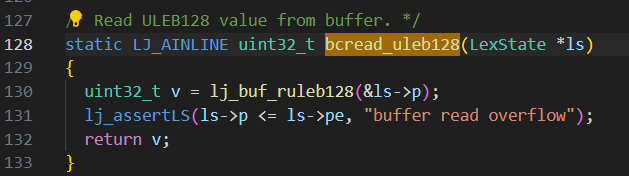
接下来就是向上跟,看看哪个函数调用了这个函数,在return的地方下一个断点,跟过去看看
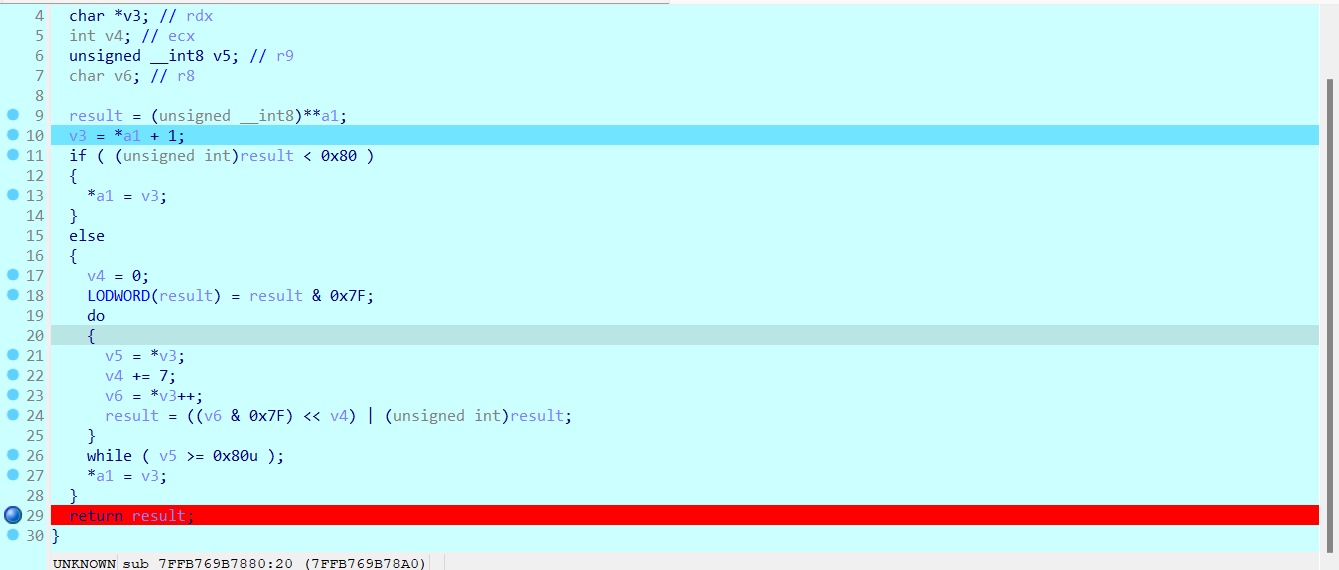
出去之后可以看到这个

上面的sub_7FFB769B7880就是刚才调用的函数(函数名不同因为重新运行了一次)
但是在这个函数内向上翻会发现函数头缺失,而且无法进行反编译,因此需要重新设定函数头

至于在什么位置设定就见仁见智了,主要是需要知道调用刚刚的函数作用是什么,也就是知道这个函数被调用的上下几段就行,不需要太纠结,简单来说就是先反编译再说(

随便设了个函数头,出来的结果是这个
使用bcread_uleb128去luajit源码中搜索,可以在lj_bcread.c中找到函数bcread_kgc,这是一个加载常量的函数
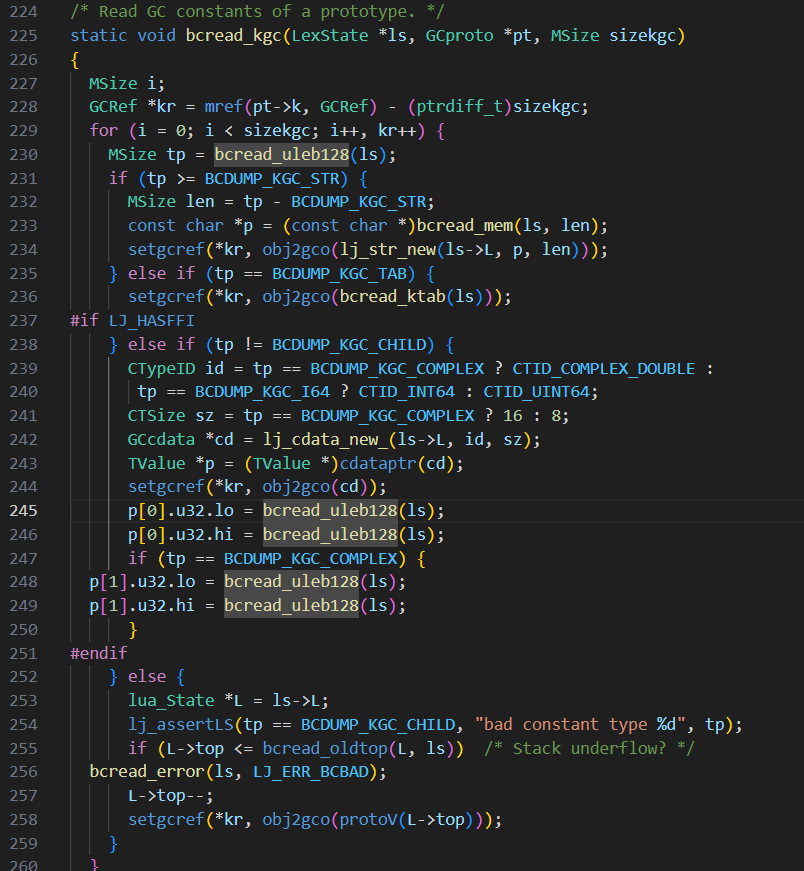
根据调试结果,发现函数将输入的数据( uleb128编码的u64 类型的数字)使用解码成u32 的值。类型的判断依据是 tp的值均为 3(这就是为什么前面和中间都有一个 03)
在lj_bcdump.c文件中可以看到tp的取值来源
1 | /* Type codes for the GC constants of a prototype. Plus length for strings. */ |
因此需要我们输入的内容实际上应该是使用uleb128编码的160位十六进制数据,它在此程序中将以u64类型、80位(10字节)为单位存储在常量部分
0x02 反编译
参考:https://www.52pojie.cn/thread-1378796-1-1.html
首先dump出luajit字节码文件,具体位置和大小存储可以在lua_loadx的第三个参数中找到

而这个第三个参数来自于luaL_loadbufferx中的StringReaderCtx ctx

而ctx这个参数的值来自于luaL_loadbuffer中的buf和size参数,这两个参数分别是字节码的起始位置和大小

参考:https://www.cnblogs.com/lordtianqiyi/articles/17000585.html
获取字节码文件
lua_load int lua_load (lua_State *L, lua_Reader reader, void *data, const char *chunkname, const char *mode);
加载一段 Lua 代码块,但不运行它。 如果没有错误, lua_load 把一个编译好的代码块作为一个 Lua 函数压到栈顶。 否则,压入错误消息
参数 reader,用来读取数据,比如 luaL_loadfilex 内部调用 lua_load 函数,reader 就是getF函数,其通过fread函数读取文件
参数 data,是指向可选数据结构的指针,可以传递给reader函数
参数 chunkname,是一个字符串,标识了正在加载的块了名字
参数 mode是一个字符串,指定如何编译数据块。可能取值为:”b”(二进制):该块是预编译的二进制块,加载速度比源块快。”t” (text):
dump出来的字节码经过010editor的bt模板识别后如下:

bt模板来源:https://github.com/feicong/lua_re/blob/master/LuaJit.bt
由此可以判断:
Luajit版本为2
是64位的luajit字节码文件,(第5字节为0x0E=b1110,其中采用2-slot frame info 模式(FLAG_FR2 = 0b00001000),后者是 64 位引入的新特性。)
dump出字节码之后就能反编译了
反编译脚本参考:https://github.com/Dr-MTN/luajit-decompiler
直接对字节码进行反编译:
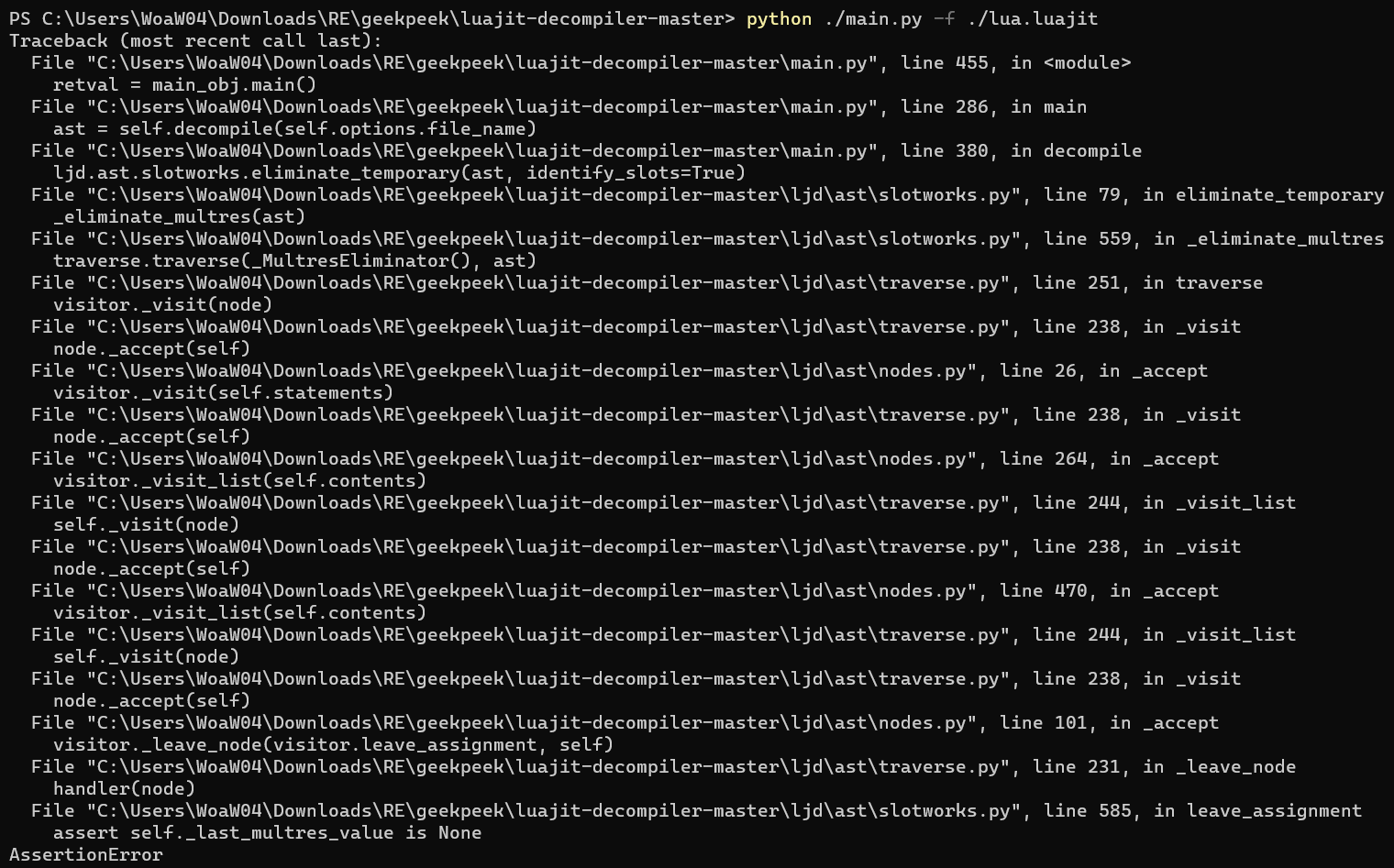
效果不理想(
此处参考佬的wp:https://www.cnblogs.com/gaoyucan/p/17577858.html
luajit中有问题的代码
1 | CALL 7 0 3 ; bit.lshift(9, 10) |
第二个参数应是返回值个数+1,对于此函数来说结果应该是2,但在这里是0
佬说其他地方基本都是2,0和2好像没啥区别,所以在反编译代码中让它将这里当2处理(
代码位置为.\luajit-decompiler-master\ljd\rawdump\code.py第47行
1 | if instruction.B_type is not None: |
然后就反编译出来了(
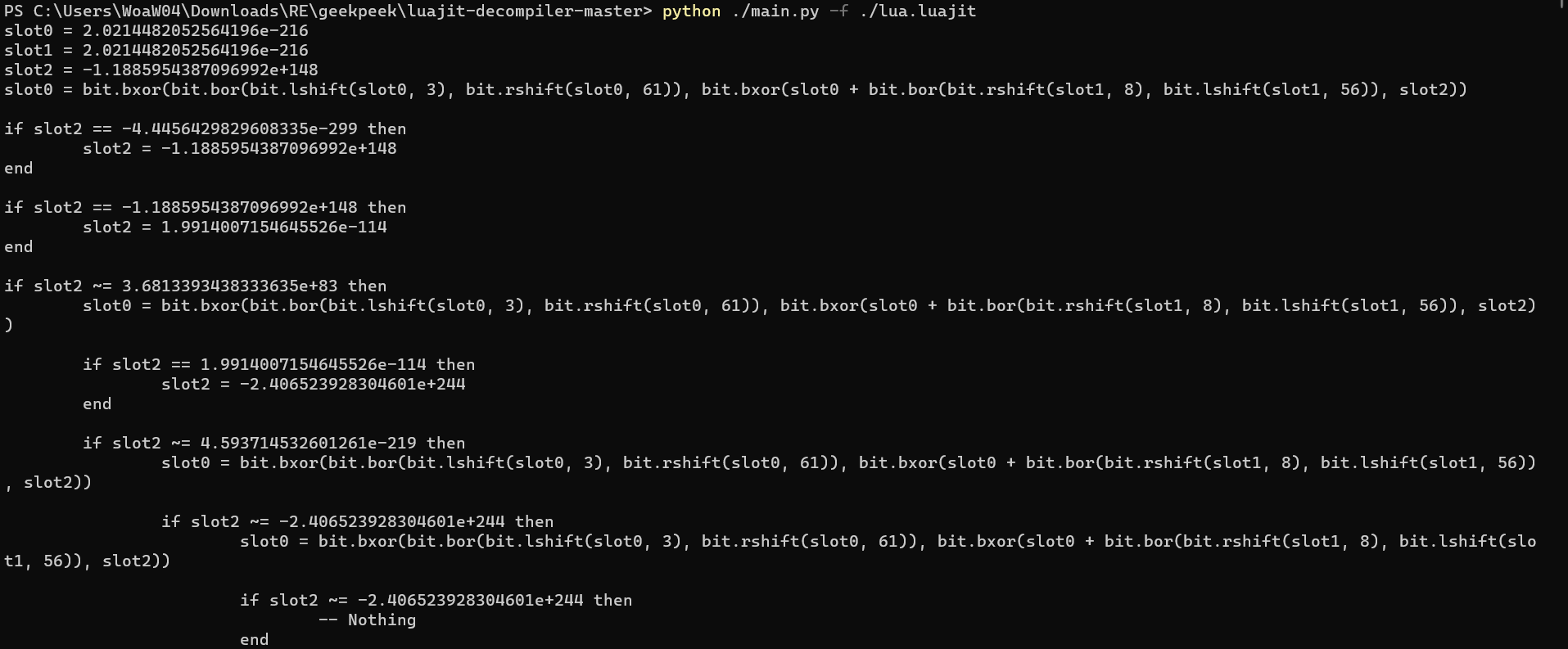
但是这个结果不对,因为slot0、slot1这些变量应该是u64类型的,所以还得改(
根据佬的wp,将.\luajit-decompiler-master\ljd\rawdump\constants.py第114行的函数返回值进行更改
1 | def _assemble_number(lo, hi): |
再运行可以得到

这次正常不少
将结果另存为out.lua
有个很坑的就是第四行一长串运算省略了中间值,需要补上
将
1 | slot0 = bit.bxor(bit.bor(bit.lshift(slot0, 3), bit.rshift(slot0, 61)), bit.bxor(slot0 + bit.bor(bit.rshift(slot1, 8), bit.lshift(slot1, 56)), slot2)) |
改为
1 | slot1 = bor(rshift(slot1, 8), lshift(slot1, 56)); |
再分析IDA反汇编代码,luaL_checkcdata函数表示从栈底开始取值,取到的分别是slot0与slot1,并判断是否是某个值。

通过运行out.lua,可以得到一共运行了32次上述4行代码,其中slot2都不同,最终可以写脚本:
1 | import leb128 |