
2023DASCTF七月赛TCP
0x00 分析
此题使用多种加密(RSA,TEA,XOR…),还加入了一点流量分析,所以做起来不太简单(
附件是一个程序(elf)和一个流量包
0x01 解
经典流程,先查壳

彳亍,直接上IDA
可以直接找到main函数

可以看到下面有一个recv函数,用于从连接的套接字或绑定的无连接套接字接收数据,接收到了一个qword_50A0,然后传给了qword_5020,最后放入了函数sub_2090进行使用

看看函数sub_2090

一步步分析,
首先是a1,应该是用户输入的某个东西
然后是a2,看不太出是干嘛的,所以先跳过
最后是a3,看到v8从0开始递增,所以合理认为a3是一个长度,而从调用的输入可以看出,a3传入是48,所以基本可以断定这是一个长度
除此之外还有一个for循环,这个循环在大循环内部,以8为条件,结合v10的变化(一段a2并进行移位),猜测起到一个分段的作用
有长度、有输入、还有一个不知道是啥的东西,感觉应该是个加密函数
实际上,这是一个RSA的加密函数,跟入sub_1F9C和sub_1E6E可以看到接了两个幂运算(__modti3),由此可以判断


__moditi3本身只有三个参数,但是汇编时会被拆成高低位,因此在IDA中会出现五个参数
可参考:https://stackoverflow.com/questions/52384456/what-does-modti3-do
既然知道这是一个RSA,那么根据密码学的相关知识,RSA一般用于加密对称密钥或者作为数字签名,根据题目意思,这个地方应该是用来加密密钥了,而recv接收的是用户输入,这个地方不可能是被加密的密钥,所以这个只能是一个公钥,毕竟公钥不怕被泄露,因此这个a3,即传入的unk_5060就是一个对称密钥了
那么就有了另一个问题:后续加解密的key哪来的呢?
跟进去unk_5060发现是空的,说明这个密钥是随机生成的,既然是随机生成的,那么就需要根据附件来进行解密,找出这个随机密钥了
打开wireshark看附件,追踪一下TCP流

根据刚才的分析,可得RSA的公钥就是第一段,而众所周知,RSA的公钥由N和e组成,怎么知道N和e的具体长度呢?
这就要看函数如何处理接收到的公钥了
从sub_2090中输入sub_1F9C的变量可知,a1被分成三段进行输入,一个是前16B,另一个是紧接着的8B,最后是其他的8B
所以在第一段中前16个字节是RSA的N,那么剩下的8个字节就是e了,最后的字节因为为全0所以不用管
因此可以得到
1 | n = "0x5fcef0e867349fc68f40763a6b0bde01" |
e和N都不是很大,可以自行分解

1 | # 此处已转换为大端 |
接着就可以把随机生成的密钥进行解码了
需要注意的是,这个RSA加密函数将这个key以8字节分段,最后生成每个段为16字节,一共6个段,即最终传输16*6=96字节的数据(结合main函数在sub_2090后的send和sub_2090的第三个参数)
1 | from Crypto.Util.number import * |
回到main函数,看看这个密钥被用来干什么了

由main函数可以看到,从用户接收的数据是v5,然后v5就和密钥被用到sub_1D9A这个函数了
合理怀疑这个sub_1D9A是解密函数

看来确实是,不过解密也被分为了两种,当字节数大于16时使用一种,字节数小于16时使用另一种
字节数十六以下的使用了一个异或,这个异或用到了随机密钥的后16位
字节数十六以上用了一个算法,跟进去看看

是看不懂的算法,搜一搜发现是一个叫做TEA的算法
参考:https://blog.csdn.net/xiao__1bai/article/details/123307059
在这里此算法使用了密钥的前32位进行操作
回到main函数
main中,服务端循环接受客户端传来的12字节作为控制码,结构是3个dword,第一个用于决定操作类型,第二个是存储偏移或校检等,第三个是有效数据长度
操作类型:1对应解密输出,2对应解密后存储,3对应输入并存储,4是输出,5执行写入的shellcode,6退出。
由于控制码都是小于16的,所以可以根据这个对控制码进行解密,并将数据进行分组
据此,写脚本初步解密流量中的密文
1 | import binascii |
流量解密后内容如下:
1 | 01 00 22 |
然后解密数据
根据解密算法,编写解密TEA的脚本如下:
1 | # 解密函数 |
解密结果如下:
1 | 01 00 22 |
最长的那一段就是判断密码的函数了
将它放入程序去分析,写个patch加到程序里面
1 | import struct |
先将hex转为intlist
1 | import ida_bytes |
然后写补丁
最后再IDA中运行(可以考虑先把基址设为0)

然后就写入了

然后转换为函数进行分析

可以看到这样的东西
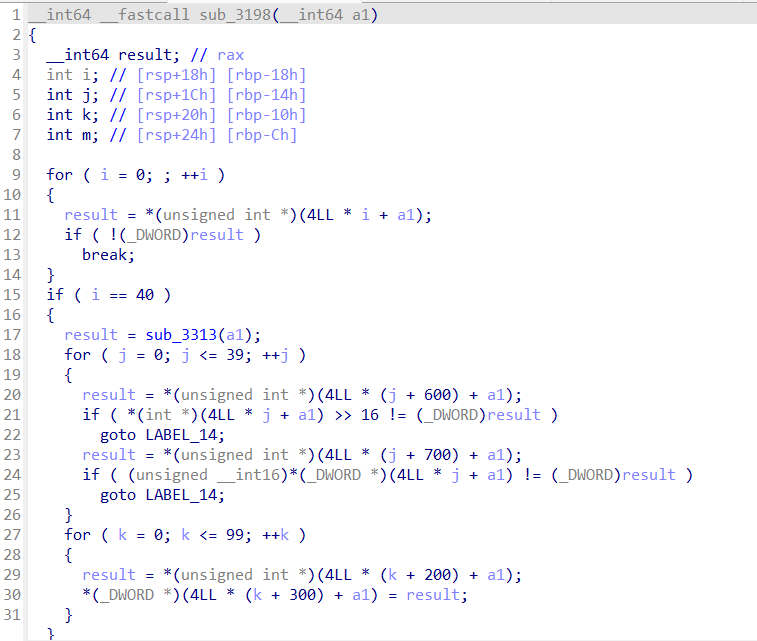
sub_3313也很重要
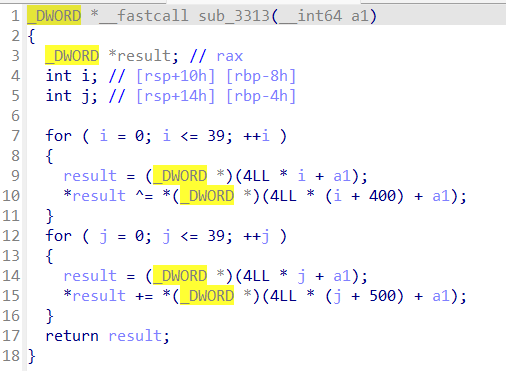
根据这两个函数,我们可以得知
这段代码分别使用了400,500,600和700偏移处的数据,判断出结果以后,再把100或者200处的字符串数据复制到300中,然后调用命令代码4的输出功能将300处的结果显示出来。
于是可以写出代码如下:
将上面的数据转换为intlist
1 | d="hex数据" |
再根据函数进行解密
1 | # 2 4 |