read_one_bit is self-explanatory: it reads one bit of the user input. More precisely, it reads a byte from stdin with getc every 8 calls, stores its bits in .data variables. Therefore, each call, it returns a new bit from the user input.
Since it performs integer division by 2324, it makes sense to view the variables I renamed x and y as coordinates. Furthermore, we can try dumping and visualizing the map as a 2324-bytes-wide image:
data = list(open('./re', 'rb').read()[0x3018: 0x3018 + 0x526990])
defshow_state(data, height, width): f = sys.stdout for y inrange(height): for x inrange(width): c = data[width * y + x] if c == 0x01: f.write('@') elif c == 0x80: f.write('$') elif c == 0x11: f.write('?') elif c == 0xec: f.write('2') elif c == 0xea: f.write('1') elif c == 0xcd: f.write('0') else: f.write(' ') f.write('\n')
_data = [] width = 122# 可变,由于vscode的输出大小只有122个字符,所以我设置成这个 height = 55# 50以后y轴就没有东西输出了 for y inrange(height): # for x in range(width): _data += data[y * 2324: y * 2324 + width] show_state(_data, height, width)
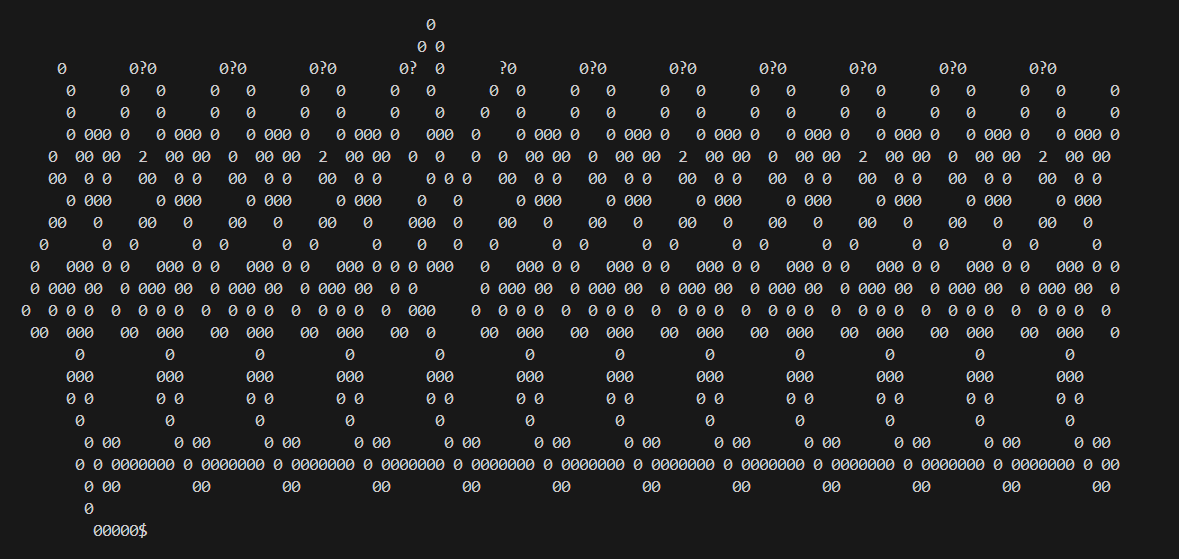
The map mostly consists of 232 of these patterns horizontally glued next to each other. Here is the same pattern in hexadecimal, where I removed null bytes for clarity.
整个图最多包含232张这样的图案,然而在此题中,第四个和第五个图案有所改变(改编了逻辑状态)
由下半可知
Some patterns have an 0xEC byte on the fifth line, some don’t and have a 0xCD instead. This may be important data in flag verification.
All the patterns have an 0x11 byte at the top center.
.text:00005644A46C7690 loc_5644A46C7690: ; CODE XREF: sub_5644A46C7570+6A↑j .text:00005644A46C7690 xor eax, eax .text:00005644A46C7692 call qword ptr [r13+0] .text:00005644A46C7696 test al, al .text:00005644A46C7698 jz short loc_5644A46C7680
It calls the function pointed by r13, which is the function pointer argument passed by main (read_one_bit). Therefore, for each of these patterns in the map, one bit of the user input is read. This confirms that the flag is indeed 232 / 8 = 29 bytes long.
defupdate(data, height, width): _data = data[:] for y inrange(height): for x inrange(width): c = data[width * y + x] if c == 0xcd: if check_pos(data, height, width, y, x): _data[y * width + x] = 0xec elif c == 0xea: _data[y * width + x] = 0xcd elif c == 0xec: _data[y * width + x] = 0xea elif c == 0x11: _data[y * width + x] = [0xcd, 0xec][values.pop(0)] elif c == 0x01: pass elif c == 0x80: assertnot check_pos(data, height, width, y, x) return _data
defcheck_pos(data, height, width, y, x): count = 0 for _x inrange(x - 1, x + 2): for _y inrange(y - 1, y + 2): if _x < 0or _x >= width or _y < 0or _y >= height or (_x == x and _y == y): continue if data[_y * width + _x] == 0xec: count += 1 return count == 1or count == 2
defshow_state(data, height, width): f = sys.stdout for y inrange(height): for x inrange(width): c = data[width * y + x] if c == 0x01: f.write('@') elif c == 0x80: f.write('$') elif c == 0x11: f.write('?') elif c == 0xec: f.write('1') elif c == 0xea: f.write('2') elif c == 0xcd: f.write('3') else: f.write(' ') f.write('\n')
_data = [] width = 66 for y inrange(26, 50): _data += data[y * 2324: y * 2324 + width]