
2024羊城杯sedRust_happyVM
0x00 前言
rust的题,主打一个看不懂,全部交由动调,动调功底要求很高
0x01 解
无壳,直接上IDA
查找字符串,

交叉索引一下去到函数sub_40B2E0

由于是rust,反编译就不看了,直接看汇编,来到input的地方
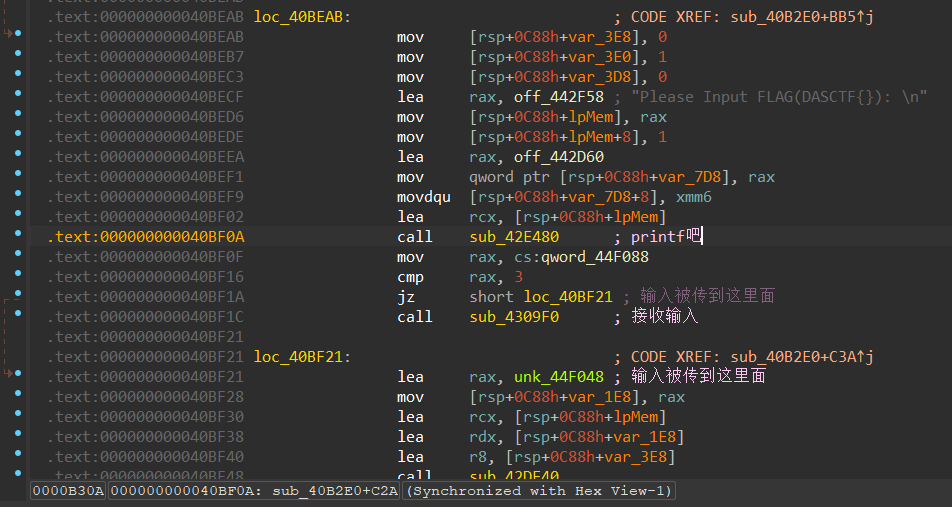
往下走可以发现两个cmp
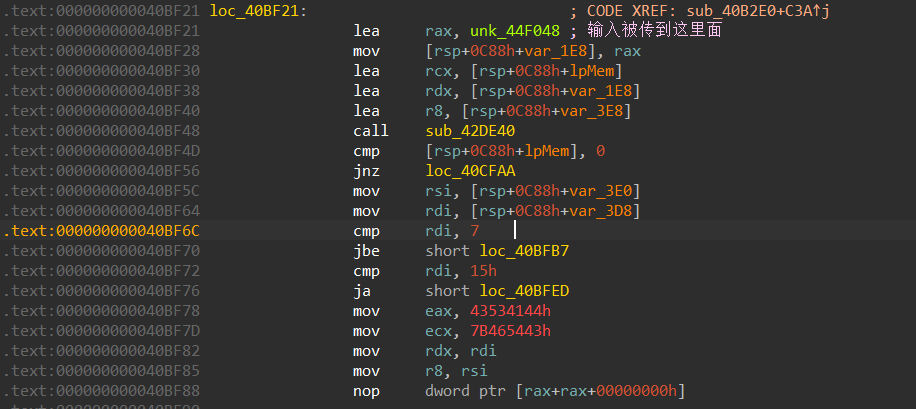
一个个试,先输入小于7的,然后再输入大于0x15的,会发现小于7的直接call了个HeapFree,因此输入要大于0x15
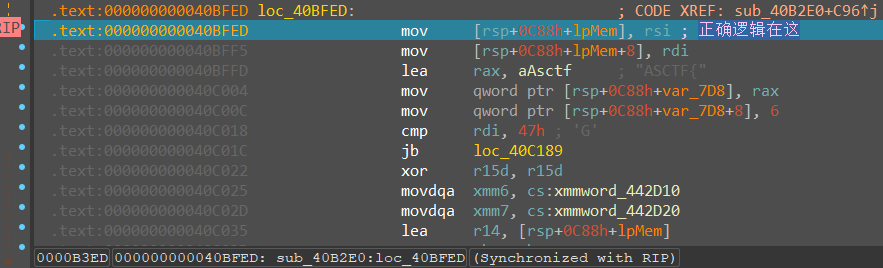
继续向下走,又一个CMP,注意这里rdi存储的是输入的长度(十六进制),发现小于0x47是正确的
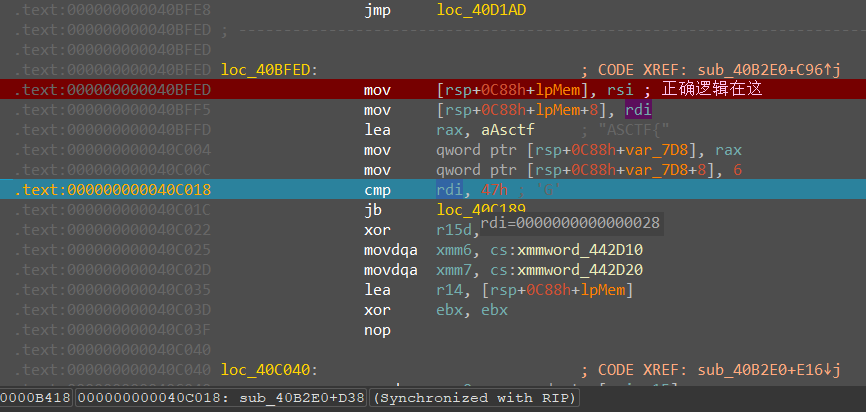
继续向下,由于下面有SIMD指令,因此打开xmm寄存器窗口便于观察
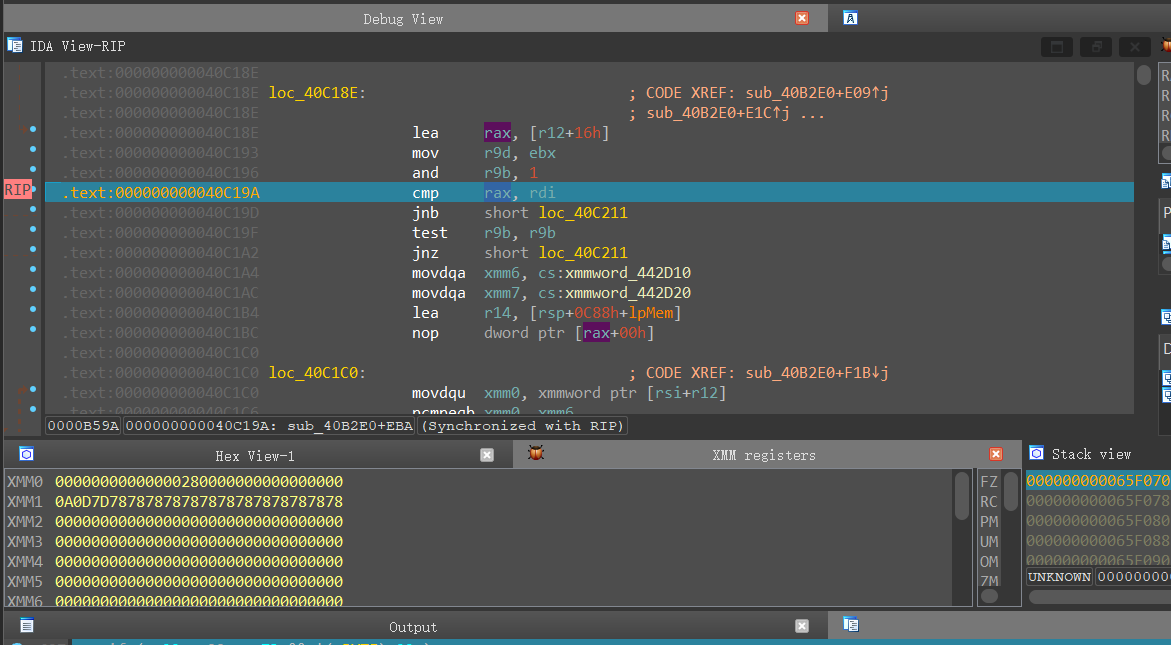
之后一直向下走,发现在这里又进行了一次对比

从上图可以发现在最后还对比了一个0x7D(即})
因此合理推断flag长度为0x28(40)个字符
重新进行调试,经过一些HeapAlloc之类的初始化(不过这个Alloc之后没几步就Free了,不知道在干啥)

一直往下走,发现只有这里才开始取输入内容
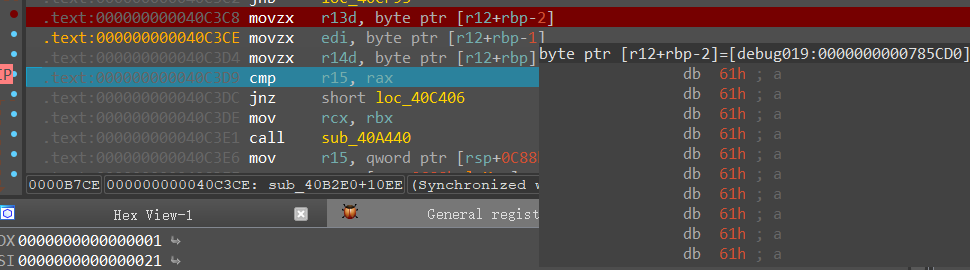
取了三个字节到三个不同的寄存器
r13d的内容丢到这里面了

edi的内容在这

r14d的内容在这

最后还要进行一次与运算
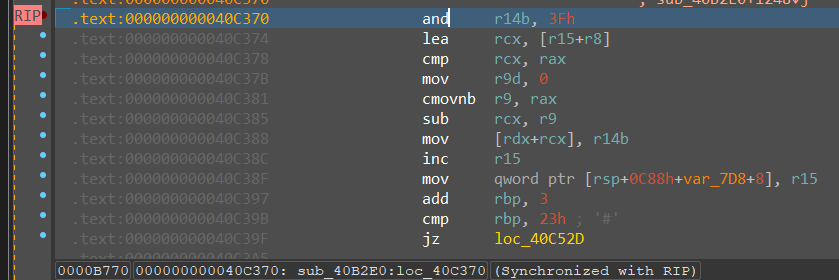
以上这些都在一个循环内,循环会对输入的全部进行计算,但是输入去掉flag头和尾只有32字节,因此最后还要补0x00,整个循环如下:
1 | input = ['0','1'] |
之后跳出循环,继续走,会发现有很多运算,下图中rsi存的就是变换后的结果,图中可以看到rsi被两次调用,分别丢进了ecx和eax,这两个寄存器经过移位,最后放入edx中,然后edx与一个值做加法,最后和rcx和r8d一起丢入函数sub_40ABA中
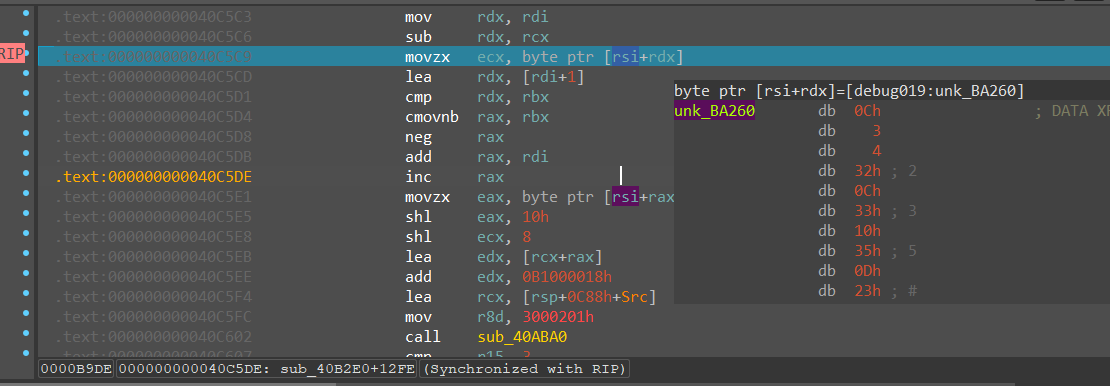
后面的流程与这段大同小异,会不断调用sub_40ABA0
进去这个sub_40ABA0看
反汇编可以看到很多switch

看不懂,继续动调(下个硬断会发现一直在一段循环,所以这边直接下在switch jmp的位置,然后一步步执行,遇到循环就下switch jmp),最后会到这个地方,一看就不太对劲
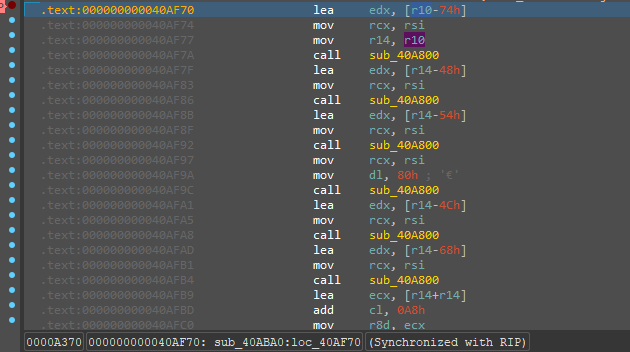
进去sub_40A800发现参数是rsi的内容

之后会在这个地方进行循环,猜测这个应该是解释器
继续动调发现后面还有调用sub_40A800的地方,且这些地方在进函数之前会使用一个rsi+0x410左右的地方
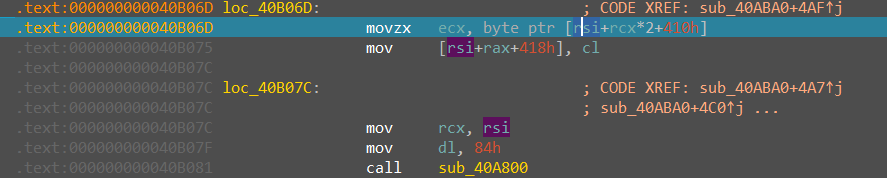
动过动调,发现这个区域会反复变化

应该是寄存器了
不得不说sub_40ABA太乱了,无法分析,只能去看看sub_40A800如何
所幸这玩意结合动调能看,虽然不是完全能看
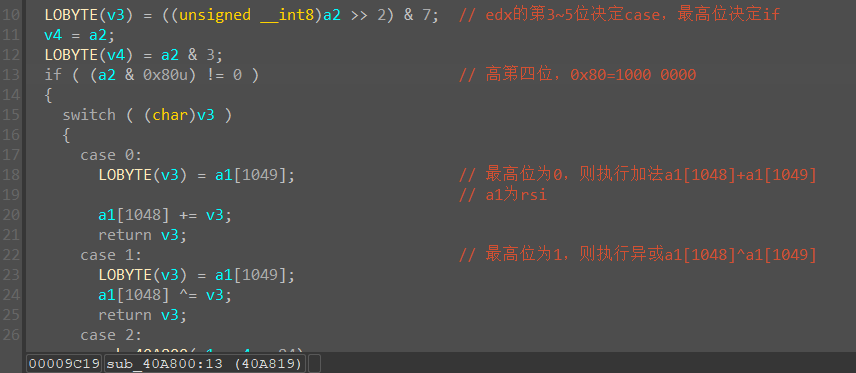
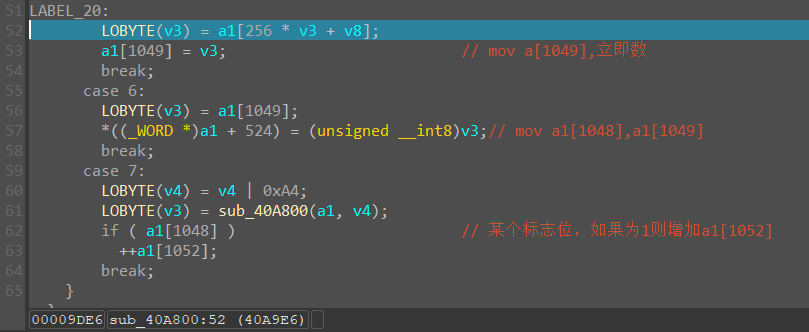
在a1[1052]处下硬件断点,会发现最后进了一个比较,下面就是成功的字符串
由此可见这个a1[1052]最后的结果要为0,所以它是一个错误数的统计,根据这个就能找到操作了
由于a1[1052]依赖于a1[1048]进行判断,而a1[1048]又与a1[1049]以及其他东西有关系,但a1[1049]和其他东西不太好跟踪,所以直接只跟踪a1[1048],其中要重点关注这个值的赋值和判断
首先是几个mov,基本都是赋值0


然后是这个add,里面的结果与输入没什么关系

之后又是几个mov也没看到输入的影子
最后在经历几次如上的循环后来到了xor

发现第一次xor的内容是输入
第二次的内容是固定的
两次xor之后就到了cmp了
这下看懂了,要获得转成四字节后的密文,只需要将执行到第一次xor时a1[1048]的值和第二次xor时al的值进行异或即可
这边学习一下IDA python的动调脚本:动调脚本化 — ida_python
以及中文互联网没有的:ida-pro-scripting-debugger-with-python-fails-on-step-over-run-to
1 | import idaapi |
最后可以得到两份密文
1 | s1 = [0x0, 0x82, 0x11, 0x92, 0xa8, 0x39, 0x82, 0x28, 0x9a, 0x61, 0x58, 0x8b, 0xa2, 0x43, 0x68, 0x89, 0x4, 0x8f, 0xb0, 0x43, 0x49, 0x3a, 0x18, 0x39, 0x72, 0xc, 0xba, 0x76, 0x98, 0x13, 0x8b, 0x46, 0x33, 0x2b, 0x25, 0xa2, 0x8b, 0x27, 0xb7, 0x61, 0x7c, 0x3f, 0x58] |
然后就是异或和四字节转三字节的操作了
1 | s1 = [0, 130, 17, 146, 168, 57, 130, 40, 154, 97, 88, 139, 162, 67, 104, 137, 4, 143, 176, 67, 73, 58, 24, 57, 114, 12, 186, 118, 152, 19, 139, 70, 51, 43, 37, 162, 139, 39, 183, 97, 124, 63, 88, 0] |
包上DASCTF{}就行了