
2020RCTFcipher
0x00 前言
一直以来都觉得不得不玩玩qemu,弄了个qemu的题来玩玩,顺便体验一下IDA9.1的魅力(?)
0x01 静态分析
给了两个文件,一个cipher,一个ciphertext
ciphertext应该就是密文了,后面多的一个0x0A应该就是换行符

至于cipher,只知道是个ELF文件,可以使用readelf -h file来查看ELF文件的具体信息
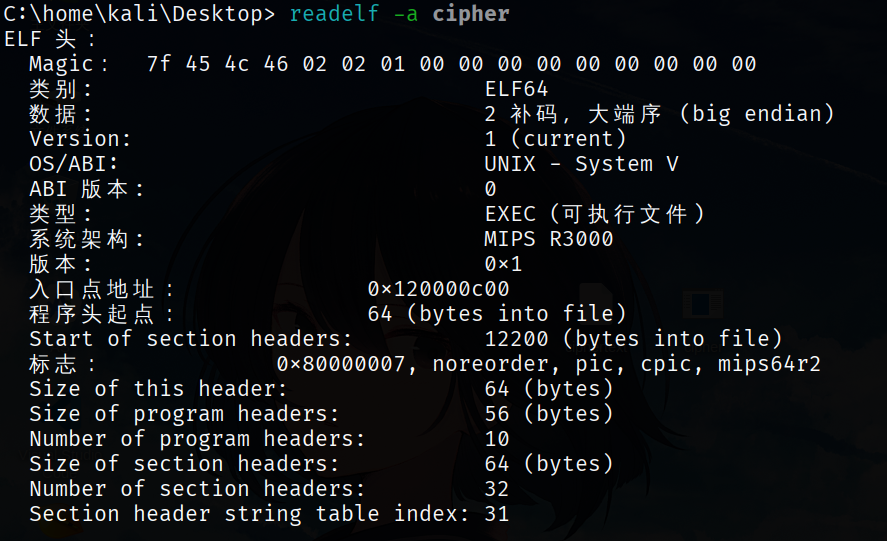
读一下可以知道是MIPS64的可执行文件,大端序
由于IDA从2021年底开始就支持了MIPS架构,所以直接拖IDA加上F5就好了,以前的还要用[ghidra](NationalSecurityAgency/ghidra: Ghidra is a software reverse engineering (SRE) framework)
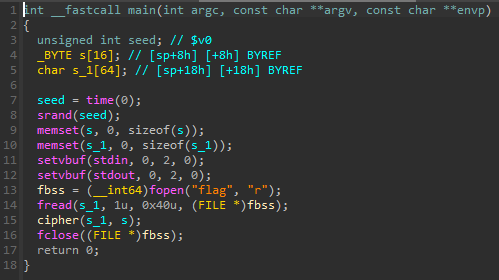
反编译可以看到读了一个flag文件的内容然后调用了cipher函数进行了加密
看看cipher函数,顺便改一下变量名
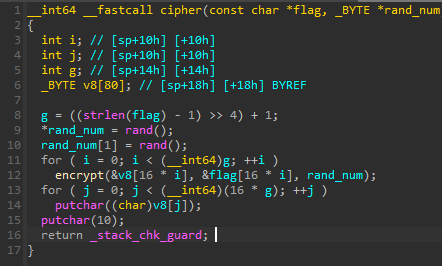
看上去是分组了,16个bytes为一组,先减一再除16后加一的作用就是让不足一组的计为一组
之后取了随机数然后丢入encrypt函数里面按组加密,最后输出内容
看看encrypt函数怎么操作的,顺便改改变量名
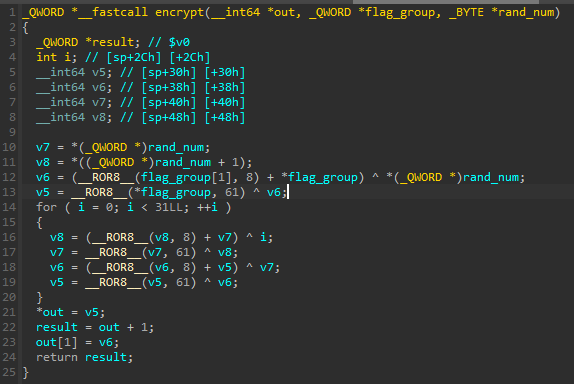
根据IDA内defs.h的[定义](IDA plugins/defs.h)
1 | inline uint64 __ROR8__(uint64 value, int count) { return __ROL__((uint64)value, -count); } |
__ROR8__就是循环右移的操作,根据给出的count来决定向右移几位
需要注意的是传入的rand_num的类型是__BYTE * ,但是后面赋值时变为了_QWORD *类型,说明传入rand_num前是有一项操作将其转为了单字节数组
那么加密过程就很明显了,转为python大概长下面这样
1 | def enc(out,flag,rand_num): |
其中rand_num[0]和rand_num[1]具体怎么获得以及最后的结果未知(主要是不知道取的哪个字节),上动调看看
0x02 动态调试
动态调试主要是要结合gdb以及qemu来进行(为了这碟醋包的饺子)
我用的是kali-linux,用的是sudo apt install qemu-user-static来安装用户态的qemu
没必要模拟整个系统(apt-get install qemu-system),因为只是为了执行单个程序,因此仅安装模拟用户态的qemu就好(apt-get install qemu-user-static)
安装好后如果是静态链接可以直接执行,但如果是动态链接则会出现以下报错

这个时候就需要安装相应的链接库了
使用apt-cache search "libc6" | grep mips64来查找MIPS64的相关库
解释一下各参数
libc6指提供标准库函数
dev指开发包,包含头文件(.h)、静态库(.a)和动态符号链接(.so),无这一参数意为仅包含动态连接库
mips32、mips64、mipsr6指支持的MIPS架构,当两个架构连在一起的时候指包内同时包含针对 两种 MIPS CPU 架构的库文件,即在一个系统中可以同时运行两种模式的程序
mipsn32指一种特殊的混合模式MIPS架构(64 位寄存器 + 32 位指针),可用于嵌入式 MIPS64 设备运行遗留 32 位软件
el指小端序,没有此参数表示使用大端序
cross指支持交叉编译,允许在非 MIPS 主机上开发针对 MIPS64/n32 架构的程序同时无需目标设备本地编译
这里安装libc6-mips64-cross即可,安装后的库可以使用dpkg -L <packagename>来查找位置,当然一默认是丢到/usr/里面的
之后使用qemu-mips64-static -L /usr/mips64-linux-gnuabi64/ cipher来指定动态链接库运行MIPS64的程序(注意在同目录下创建一个flag文件)

可以看到内容被加密了
运行起来之后就是看怎么调试了
这边用IDA连接GDB进行远程调试
使用qemu-mips64 -L /usr/mips64-linux-gnuabi64/ -g 23946 ./cipher > out在23946端口开放gdb调试
启动后qemu阻塞并等待调试器连接
此时回到IDA,选择Remote GDB Debugger
然后要调一下应用路径,并让程序在开始调试和入口点处停下
没反调,下个断点就能直接跑了
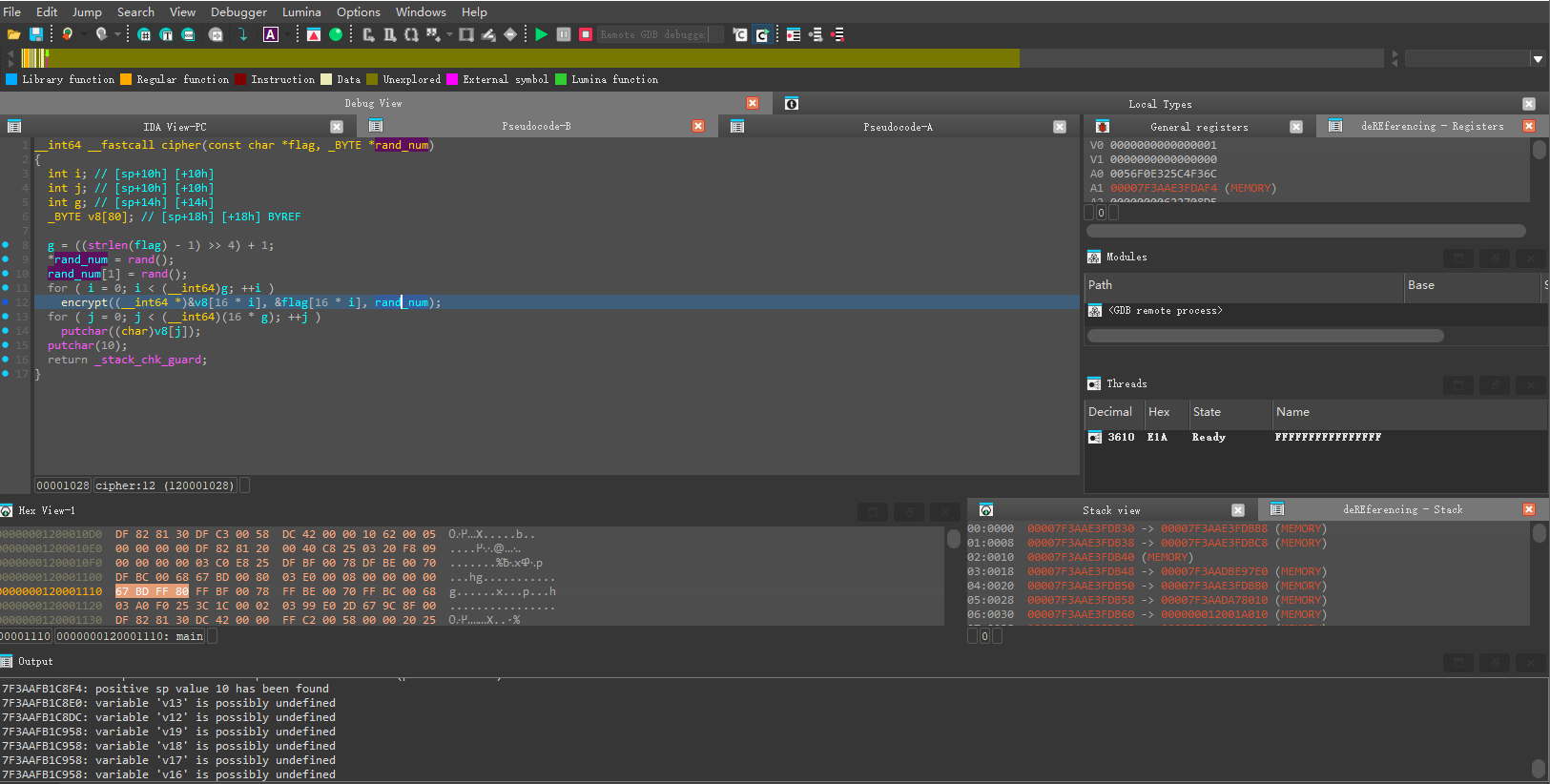
尽量看汇编,IDA虽然能反编译但是执行起来还是有点问题的(在反编译窗口用F7步入好像会崩溃),然后尽量看寄存器窗口,其他基本不准。
先看rand函数赋值的地方
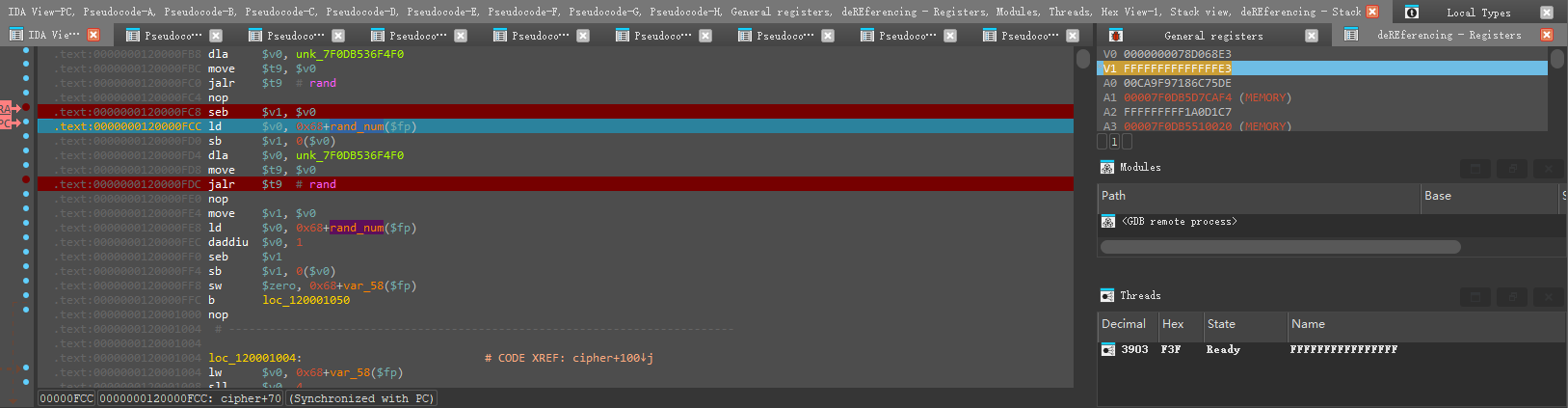
第一次调用rand函数可以发现只取了最后一个字节(rand1),并进行了符号扩展
SEB(Sign Extend Byte) 指令的作用是将一个寄存器中的字节(8位)进行符号扩展,并将结果存储在目标寄存器中。
- 符号扩展:根据这个 8 位值的最高位(第 7 位,符号位):
- 如果最高位是
0(正数或零),则用0填充目标寄存器rd的第 8 位到第 31 位。- 如果最高位是
1(负数),则用1填充目标寄存器rd的第 8 位到第 31 位。
第二次也是一样的取了最后一个字节(rand2),不过先用了move指令再到seb指令
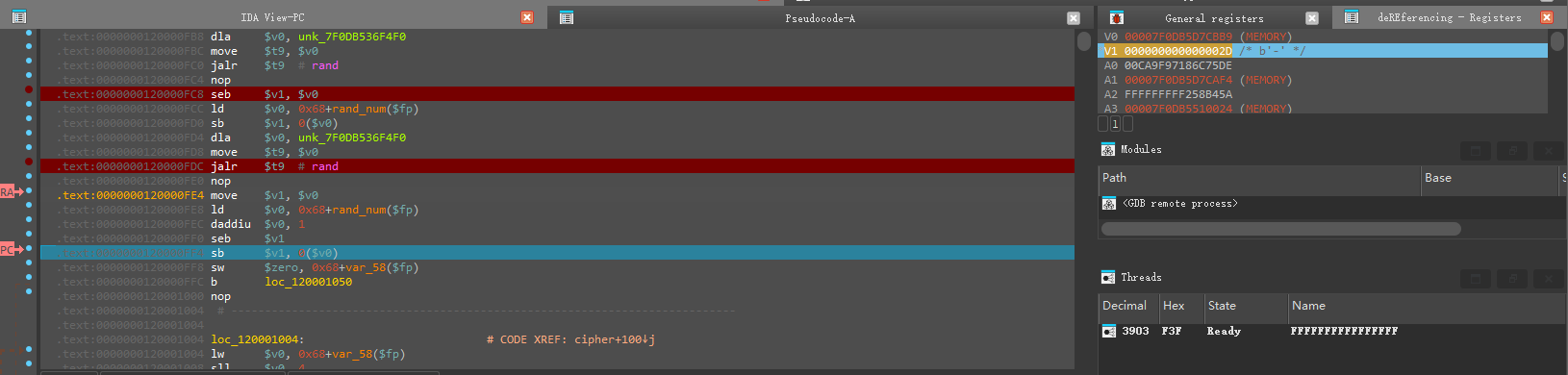
之后再进入encrypt函数看看,在这个位置用F7
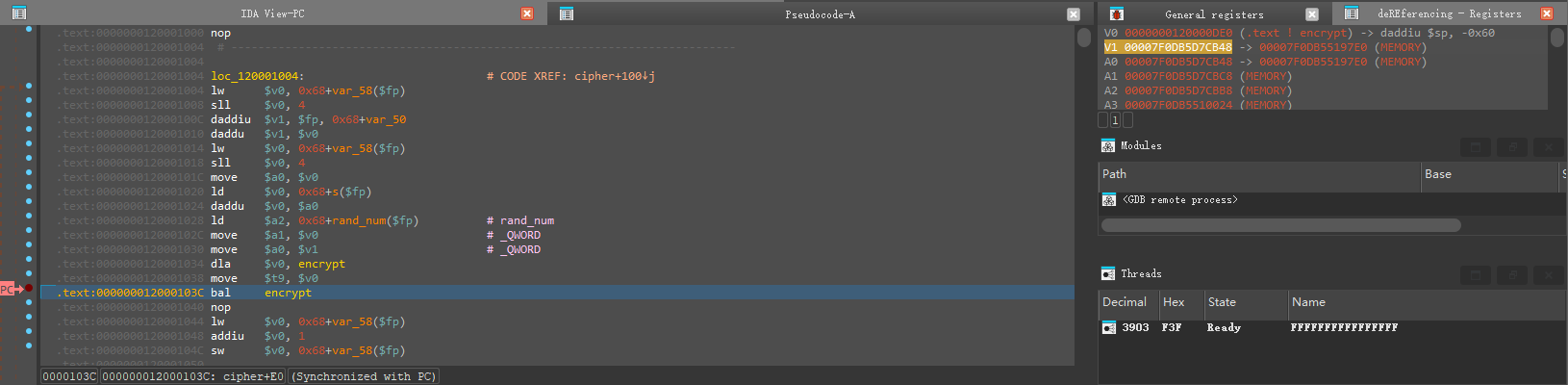
进来之后可以用F5加Tab的方法来定位v7和v8,当然也可以用Synchronize with来定位具体的汇编行
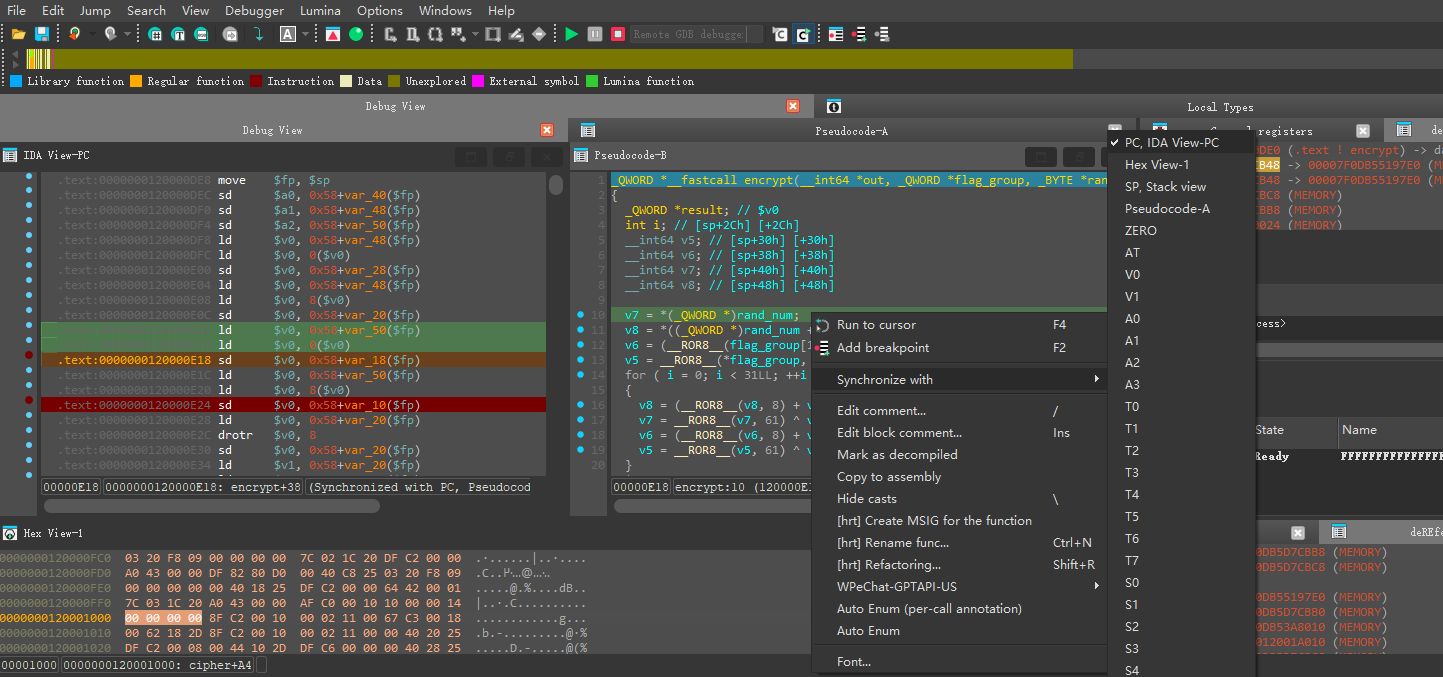
由此可以知道对v7赋值对应的是120000E18地址执行完毕,对v8赋值对应的是120000E24执行完毕
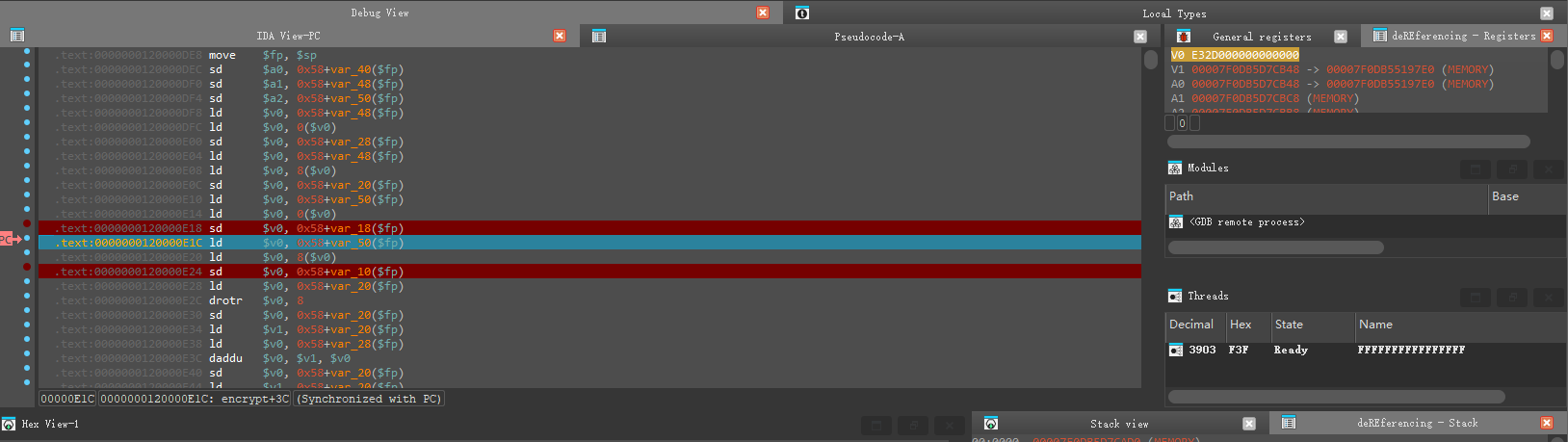
让其执行完可以发现v7的值是rand1 << 56 + rand2 << 48
而v8的值为0
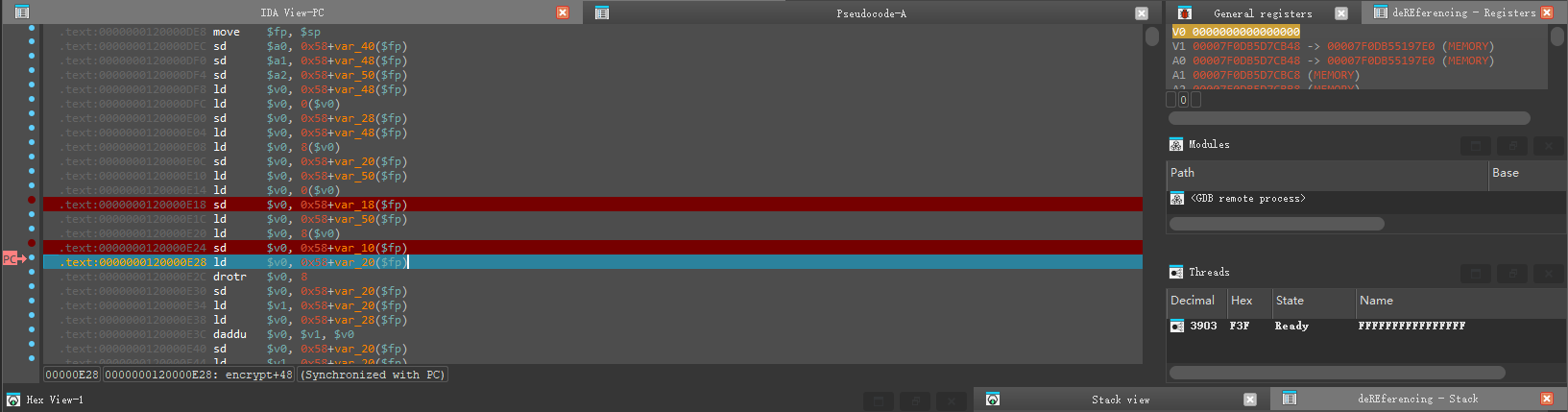
因此结果就比较明朗了,v7 = rand[0] = rand1 << 56 + rand2 << 48,v8 = rand[1] = 0
根据上面总结的加密(我复制到这来了)
1 | def enc(out,flag,rand_num): |
v7和v8用的是time(0)作为seed,因此免不了爆破了
爆破时的每次尝试可以得到一组假定的key(v7,v8),经过31轮的迭代,可以得到最后一轮的v7,v8
由于已知密文,即最后一轮迭代得到的的v5,v6;并可以以爆破的方式假定v7从而求出最后一轮的v7,v8.
可以通过v5 = ror64(v5, 61) ^ v6得到上一轮的v5 = rol64(v5^v6,61)
再通过v6 = (ror64(v6, 8) + v5) ^ v7得到上一轮的v6 = rol64(((v6^v7)-v5),8)
再通过v7 = ror64(v7, 61) ^ v8得到上一轮的v7 = rol64(v7^v8,61)
再通过v8 = (ror64(v8, 8) + v7) ^ i得到上一轮的v8 = rol64(((v8^i)-v7),8)
以此类推就可以得到flag了
因为每轮只对16Bytes进行操作,因此可以先对密文的前16Bytes解码,得到正确的v7后再解码剩下的,以避免每次都全解密一遍
1 | import struct |